
TL; DR:
1. JLPT vocab lists suck (all of them).
2. The ones used by KanjiBox now suck a little bit less, thanks to the magic of statistics and computational linguistics.
Long version:
A surprising amount of advanced NLP nerdery and algorithmic magic go into the making of KanjiBox, the details of which are usually spared to you, the blissfully ignorant user, as I believe in the important usability idea of “complex to design, easy to use”.
Nevertheless, I figured I’d share the details of my latest endeavour, for the sake of the handful of people with a combined interest in Japanese-learning, JLPT exam, language processing and all-out statistical geekfests:
1. There are no good JLPT lists
As everybody knows, there are no longer any official JLPT lists. Which hasn’t stopped people from making and using them.
For our sake, we will just pretend that, were they to exist, such lists would look roughly like those of the old-format exam (with N2 inserted halfway between the old J2 and J3, and a few adjustments within each level for better cohesion).
But even if we accept this reasonable assumption (shared by KanjiBox and 99% of all Japanese methods/software/websites out there), the resulting JLPT vocabulary lists are appallingly bad: miscategorised words, rare readings, obsolete kanji spellings, level overlap etc. etc. All typical signs of data that has been automatically parsed and imported from one source to the next, a few million times, with limited human oversight.
KanjiBox’s lists were created, 5-some years ago1, then regularly compared to a number of other lists used by miscellaneous Japanese-learning websites for the sake of improvement. It quickly became clear that all these lists were near-identical: all traceable to some unique source, all containing the same obvious mistakes and outliers. KB’s lists were greatly improved by a few rounds of automated cleaning and, most importantly, by the kind contributions of hundreds of users who took the time to report issues through the in-game suggestion button. And yet, they still sucked (albeit slightly less than others).
2. How bad is it?
Let me illustrate:
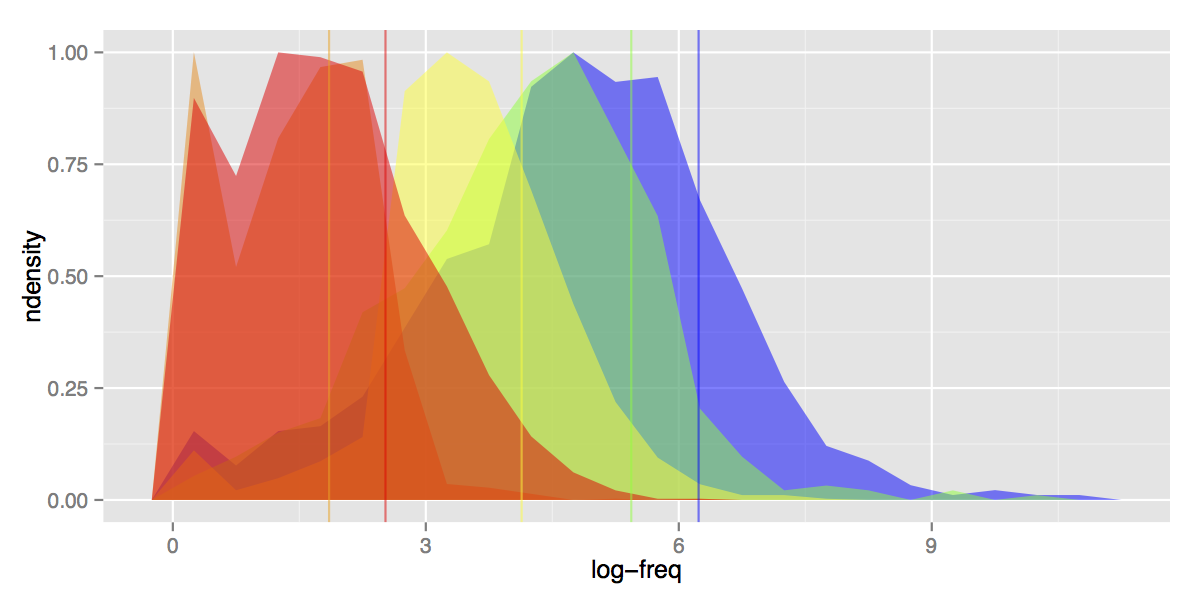
JLPT levels (before fixing)
This nice colourful figure shows the (scaled) density distribution of word log-frequency for each JLPT levels.
Also, because the horizontal axis (word frequency) uses a log-scale, each horizontal unit represents an exponential increase: word frequency grows by about 20 for every 3 horizontal units (words at position 9 are about 8000 times more frequent than at position 1). Using log-scale is mostly a visual trick to make the plots more condensed and readable, but it also makes sense from a computational linguistics perspective, to compensate for the power-law effect.
Vertical lines represent averages for each level: for example, N5 entries appear on average 510 time through the corpus (6.2 in log-scale), while N4 entries have an average frequency of 229 (5.4 in log-scale).
Come back: I promise this is about as technical as we’re gonna get for the rest of this post.
Looking at this neat little plot tells us a lot about JLPT lists level partitions (and why they currently suck):
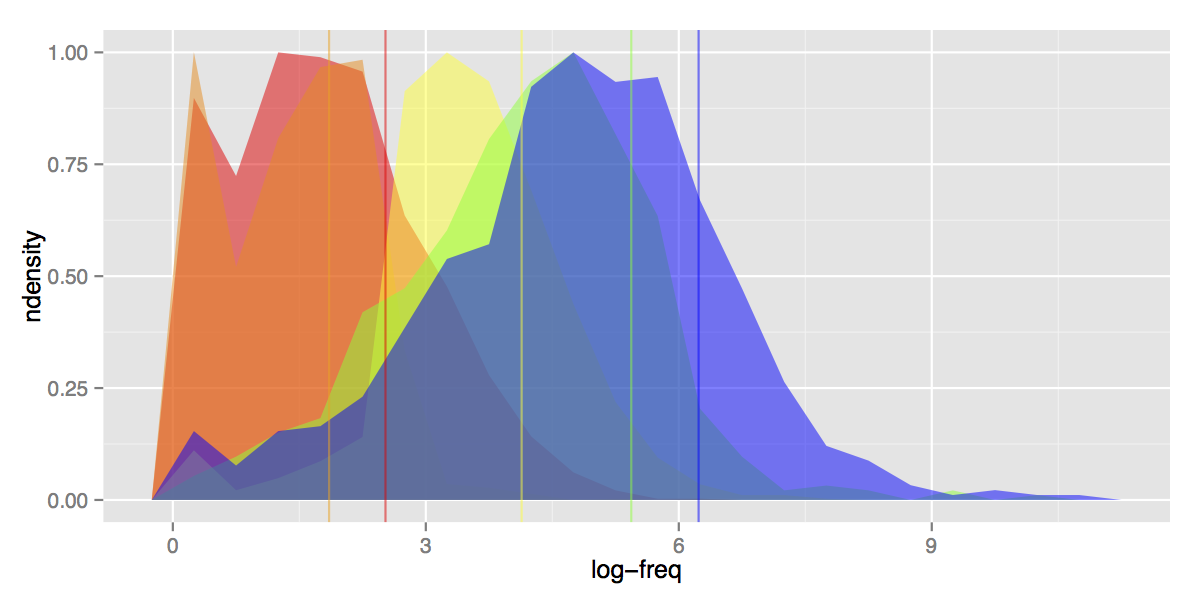
- Separation between levels: while frequency overlap is to be expected, we would also expect the bulk of each level to be clearly separate from the next. That is, words in N4 should (overall) be less frequent than N5 and so on. That’s not particularly the case. Of all the levels, N3 is the only one to stand out cleanly, and there’s a reason for that: it was artificially generated by dividing the former N2 level, using the very criteria we are plotting here (word frequency, along with some other factors and lots of manual touch-up). On the other hand, N5-N4 and, most importantly, N2-N1 are near-undistinguishable.
- In fact, N2 and N1 are such a mess, that the average frequency for N2 is much lower than N1: on average N2 words are less common than N1 words.
- Long tails on the right: levels all the way to N3-N2 have tails on the right that extends long past the average frequency of N5. This means that words supposedly belonging to N2 level appear more often in regular Japanese text than half of all N5 words. Probably shouldn’t happen.
- Long tails on the left: same problem in the opposite direction. Words supposedly belonging at N5 level are rarer than half the words in N3 or even N2 levels (easier to see if we flip the depth order of the plots).
- Bump of zero-frequency words: a particular case of the point above, and an artefact of the “small” size of our corpus2. All levels contain a large number of terms that do not appear anywhere in the corpus. This would be expected for higher levels (N1-N2), but less so for N5.
{kind=link}
All the above problems are down to two interconnected reasons: 1. inaccurate JLPT lists (erroneous level assignations) and 2. bad corpus quality (erroneous word counts). Fixing 1 requires fixing 2, which brings us to this small digression on Japanese text parsing:
3. Parsing Japanese and Counting Words
A great (and thoroughly abused) way to evaluate how common/useful a word is in a language, is to look for its frequency in certain categories of documents: news articles, Wikipedia, web pages… Each one with its upsides and downsides: news or wikipedia articles are easy to obtain in large quantities, but are strongly biased toward certain levels of speech and technical domains that you are very unlikely to meet in casual conversation.
My personal preference (and the data I used for the plots in this entry) goes to the Tanaka corpus, now part of the Tatoeba project. Although historically of uneven quality (but much improved since its beginnings), the sentences in the Tanaka corpus tend to be varied and more representative of a wide range of language registers than other available corpora.
The standard way to go about counting word frequencies in a corpus is: 1. turn sentences into individual “tokens” (words or group of words treated as units) 2. do some chunking to lump together small variations (plural forms, verb conjugation etc) 3. index all tokens 4. count the total number of occurrence of each token.
Unlike many other languages where tokenising is as trivial as separating at spaces and punctuation, Japanese text is no fun to work with. Not only is there no space (and a lot less punctuation), but it is very unclear what can define a token:
Is 「一般的」 two tokens (「一般」+「的」) or a single token? And if we consider it to be a single token (it does have a separate entry in most dictionaries after all), then what about all other words with the 「的」suffix? And if we always count 「的」 as part of the token that precedes it, does it mean that its frequency count is zero?
Millions of fun questions like that.
Assuming you’ve achieved optimal separation, you then have to deal with the unique problem of Japanese homographs and heteronyms. Languages like English have few homographs (words with identical spelling but different meaning) and even less homograph heteronyms (homographs with different pronunciations), written Japanese, thanks to its tortuous origins, has thousands of them:
Should 「今日は」 be tokenised into 「きょう」+「は」, or 「こんにちは」, or even 「こんじつ」+「は」
Does 「私」 stand for 「わたし」, 「わたくし」, 「あたし」 or one of its three hundred million other readings?
In some cases, one tokenisation is more likely than another, but this is little help when your goal is precisely to estimate the respective frequency of either one. To properly estimate what kanji/reading/meaning is attached to a given token in Japanese text, context interpretation is a requirement. And when even context is unhelpful, one often has to take an educated guess based on additional info (such as a priori knowledge on the frequency and usage of each form).
Parsing Japanese text at such a level that it can distinguish between different reading and usage of words is a non-trivial task requiring fairly advanced software…
Luckily, open-source, machine-learning tool Mecab does this pretty damn well3. Yay!
Unfortunately, Mecab is far from perfect, and will mess up a good 5-10% of tokens. Booh.
Using token counts from a straight-up Mecab parse of your corpus, is the best way to find yourself with very skewed statistics that ignore certain idiomatic forms or alternative readings (or sometimes, only feature one alternate reading while ignoring the more common form). And this accounts for part of the problems popping up in the graph above.
Many, many, work hours of script-writing and manual parse fixing later…
4. Back to JLPT sets
Even after fixing the parsing for a few thousand words (and greatly improving the reliability of the ‘Example Sentence’ feature in the process), many of the problems listed above were still showing: fixing them would presumably directly improve the quality and coherence of JLPT sets. And unfortunately, the only way to do so was to go through them one by one manually.
Cue many months spent with Daijirin, Daijisen and the Green Goddess… And a lot of hours spent browsing Chiebukuro4…
All in all, about 600 words and alternate spellings have been shuffled around JLPT sets (some moved to a lower level, other booted out entirely).
Then, I reviewed another few hundred words with a frequency count far outside of the average of their level5 and moved them to a better-fitting level. There were some exceptions, such as long idiomatic turns of phrases (‘ごちそうさま’, ‘いってらっしゃい’…) that tend to not appear much in written text despite being fairly common, but there were also lots of obviously miscategorised words:
Why was far-from-basic word ‘茶わん’: N5, but words like ‘私たち’ or ‘こんばんは’: N3 and above??
And this is the final result:
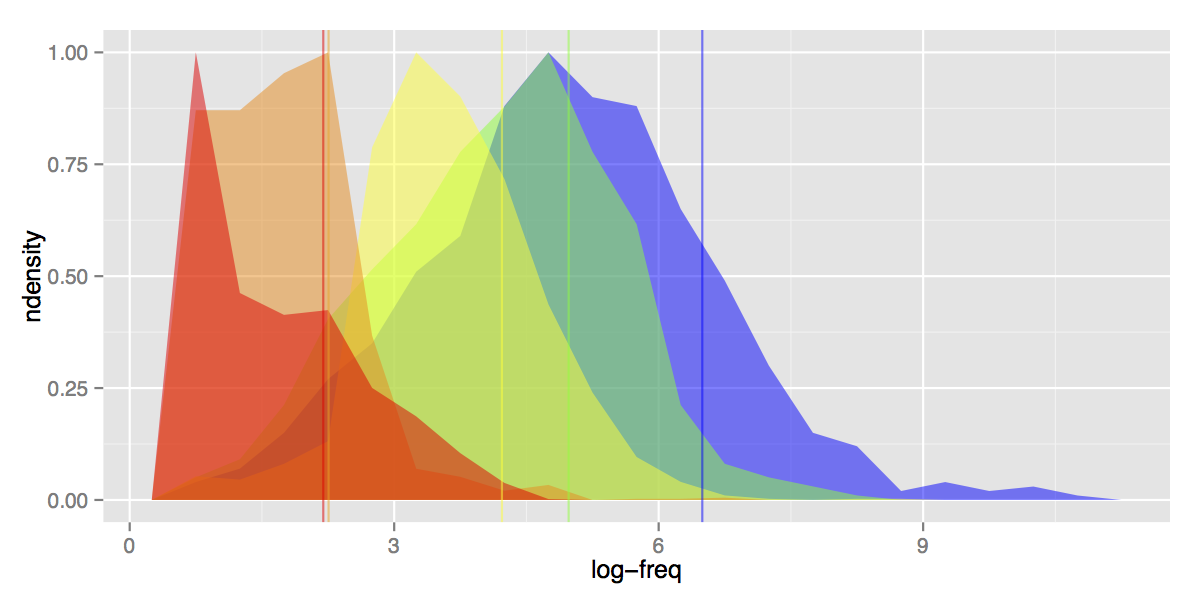
JLPT Levels (after fixing)
As you can see: the tails have considerably shortened (less outliers for each level), N5 and N4 are a little farther apart, N1 and N2 are a lot farther apart (with N1′s average frequency now lower than N2′s, as it should be in a sensible world).
Granted, these are some subtle visual changes: the levels could still afford to be a lot better dissociated. But JLPT follows other imperatives than word frequencies and my goal was not to redefine the exam entirely, merely give it some more coherence. And with over a thousand word changes, it should definitely make a difference in your revision list.
Note: In addition to being used by the online app (and the latest version of the iOS app), these (fixed) JLPT sets are publicly available to all users of KanjiBox at this page (Elite users can even suggest further corrections).
- Originally based on Wikipedia, if my memory isn’t failing me. [↩]
- if by small, we mean still over a hundred thousand sentences and a few million tokens [↩]
- In fact, Tanaka corpus used to come pre-parsed by Mecab [↩]
- Pro tip: if you are ever wondering about usage/spelling/reading of a Japanese word, typing the word, or its variants, plus ‘読み方’ or similar term into Chiebukuro’s search box, will practically always give you the answer. [↩]
- Generally went by means and standard deviation as a way to estimate what constituted “abnormal” level assignation. [↩]